Modeling and capturing the 3D spatial arrangement of the human and the object is the key to perceiving 3D human-object interaction from monocular images. In this work, we propose to use the Human-Object Offset between anchors which are densely sampled from the surface of human mesh and object mesh to represent human-object spatial relation. Compared with previous works which use contact map or implicit distance filed to encode 3D human-object spatial relations, our method is a simple and efficient way to encode the highly detailed spatial correlation between the human and object. Based on this representation, we propose Stacked Normalizing Flow (StackFLOW) to infer the posterior distribution of human-object spatial relations from the image. During the optimization stage, we finetune the human body pose and object 6D pose by maximizing the likelihood of samples based on this posterior distribution and minimizing the 2D-3D corresponding reprojection loss. Extensive experimental results show that our method achieves impressive results on two challenging benchmarks, BEHAVE and InterCap datasets.
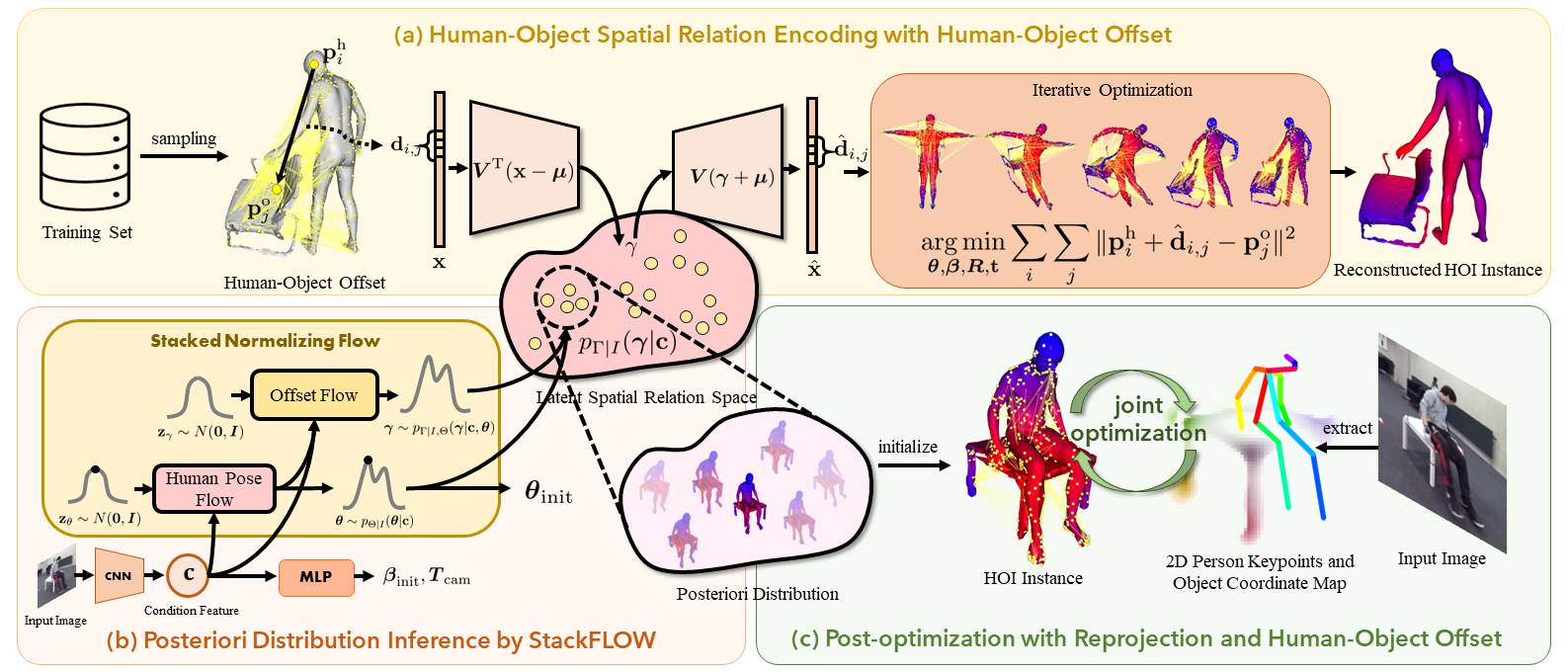
Main framework for our method. (a) We use human-object offset to encode the spatial relation between the human and the object. For a human-object pair, offsets are calculated and flattened into an offset vector x. Based on all offset vectors calculated from training set, the latent spatial relation space is constructed using principle component analysis. To get a vectorized representation for human-object spatial relation, the offset vector is projected into this latent spatial relation space by linear projection. Inversely, given a sample γ from this latent spatial relation space, we can reproject it to recover offset vector xˆ. The human-object instance can be reconstructed from xˆ by iterative optimization. (b) With pre-constructed latent spatial relation space, we use stacked normalizing flow to infer the posteriori distribution of human-object spatial relation for an input image. (c) In post-optimization stage, we further finetune the reconstruction results using 2D-3D reprojection loss and offset loss.













@inproceedings{ijcai2023p100,
title = {StackFLOW: Monocular Human-Object Reconstruction by Stacked Normalizing Flow with Offset},
author = {Huo, Chaofan and Shi, Ye and Ma, Yuexin and Xu, Lan and Yu, Jingyi and Wang, Jingya},
booktitle = {Proceedings of the Thirty-Second International Joint Conference on
Artificial Intelligence, {IJCAI-23}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
editor = {Edith Elkind},
pages = {902--910},
year = {2023},
month = {8},
note = {Main Track},
doi = {10.24963/ijcai.2023/100},
url = {https://doi.org/10.24963/ijcai.2023/100},
}